
BF-NAICS 2021
#resources
Эта неделя запомнилась мне участием в форуме BF-NAICS 2021. На протяжении трёх дней представители нейронауки, сферы искусственного интеллекта и теории сложных систем обсуждали текущие достижения в фундаментальных исследованиях и прикладных разработках. В следующих постах поделюсь заметками на основе некоторых докладов.
Ссылки на видеозаписи пленарных лекций представлены ниже:
13 сентября:
- Стефано Боккалетти, "Процессы и динамика в сетях за пределами парных взаимодействий";
- Андрей Зиновьев, "Многомерная геометрия сложных молекулярных данных";
- Константин Анохин, "Нейронный код: в поисках клеточных принципов кодирования когнитивной информации";
14 сентября:
- Итамар Прокачча, "Диффузионная ограниченная агрегация: создание моделей фрактального роста";
- Иван Оселедец, "Геометрия в задачах машинного обучения";
- Василий Ключарев, Анна Шестакова, "Машинное обучение в когнитивной нейровизуализации";
15 сентября:
- Михаил Иванченко, "Динамика старения: сложные системы, сети, биомаркеры";
- Михаил Бурцев, "Вызовы для глубокого обучения";
- Михаил Лебедев, "Управление нейроинтерфейсом в разных режимах: «ловкость рук» и нейропластичность";
- Павел Балабан, "Формирование, поддержание и регуляция памяти".
#resources
Эта неделя запомнилась мне участием в форуме BF-NAICS 2021. На протяжении трёх дней представители нейронауки, сферы искусственного интеллекта и теории сложных систем обсуждали текущие достижения в фундаментальных исследованиях и прикладных разработках. В следующих постах поделюсь заметками на основе некоторых докладов.
Ссылки на видеозаписи пленарных лекций представлены ниже:
13 сентября:
- Стефано Боккалетти, "Процессы и динамика в сетях за пределами парных взаимодействий";
- Андрей Зиновьев, "Многомерная геометрия сложных молекулярных данных";
- Константин Анохин, "Нейронный код: в поисках клеточных принципов кодирования когнитивной информации";
14 сентября:
- Итамар Прокачча, "Диффузионная ограниченная агрегация: создание моделей фрактального роста";
- Иван Оселедец, "Геометрия в задачах машинного обучения";
- Василий Ключарев, Анна Шестакова, "Машинное обучение в когнитивной нейровизуализации";
15 сентября:
- Михаил Иванченко, "Динамика старения: сложные системы, сети, биомаркеры";
- Михаил Бурцев, "Вызовы для глубокого обучения";
- Михаил Лебедев, "Управление нейроинтерфейсом в разных режимах: «ловкость рук» и нейропластичность";
- Павел Балабан, "Формирование, поддержание и регуляция памяти".
bfnaics.kantiana.ru
BF-NAICS 2022
Балтийский форум: нейронаука, искусственный интеллект и сложные системы
Автоматизация мета-анализов
#resources #tools
Решила поделиться тремя полезными ресурсами, которые могут пригодиться как на этапе планирования исследования, так и на этапе интерпретации уже полученных результатов. Их основной принцип заключается в автоматическом объединении результатов проведённых ранее исследований.
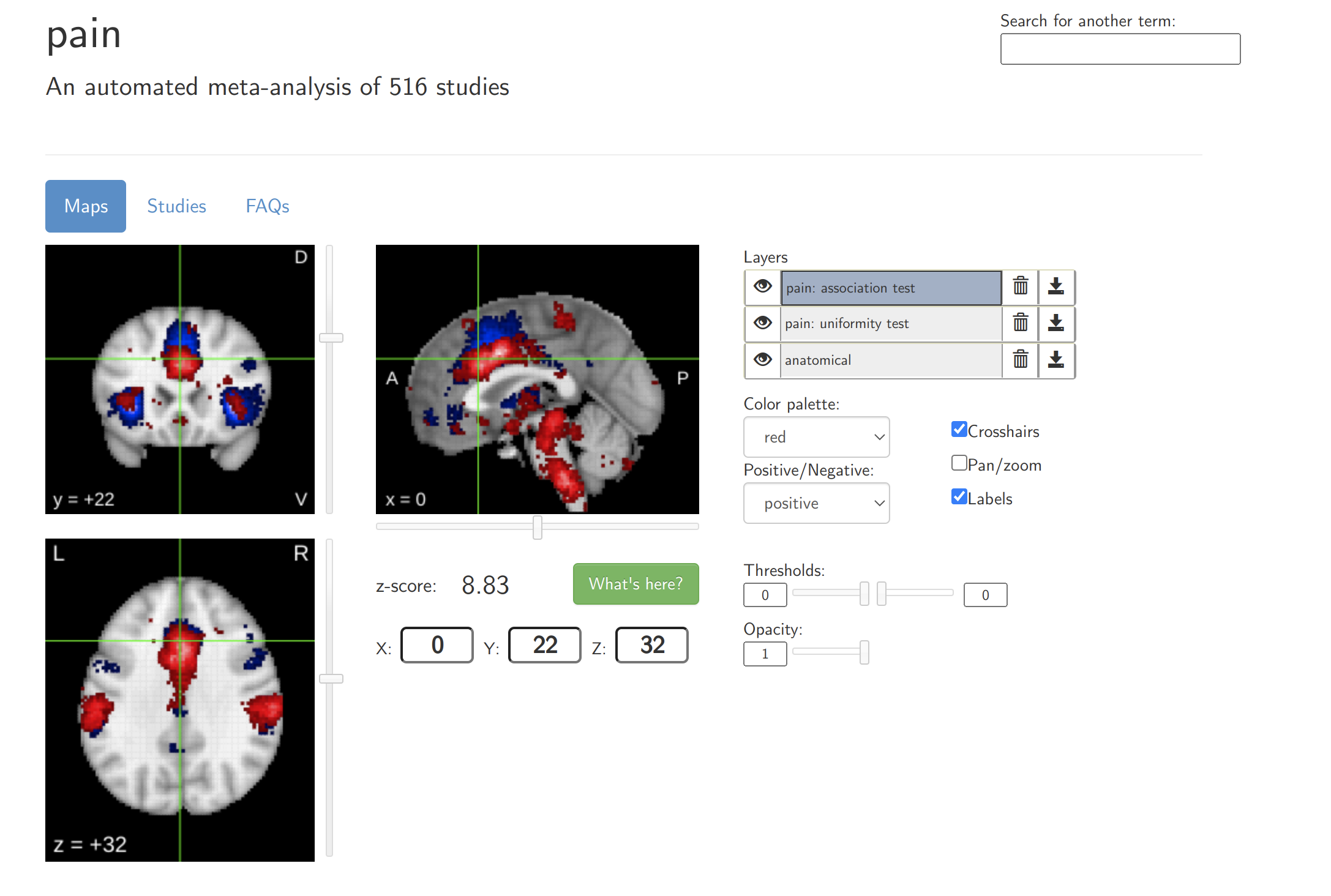
1. Neurosynth: соотносит психологические параметры с активацией или функциональной связностью на фМРТ.
2. NeuroQuery: на основе свободного текстового запроса (например, "spatial memory in prefrontal cortex ") предсказывает распределение активности фМРТ. Основное отличие от Neurosynth заключается в том, что позволяет проанализировать запрос, выходящий за рамки существующей литературы.
3. ERPscanr: соотносит всевозможные компоненты вызванных потенциалов с когнитивными доменами (например, восприятием или памятью) или с конкретными расстройствами.
#resources #tools
Решила поделиться тремя полезными ресурсами, которые могут пригодиться как на этапе планирования исследования, так и на этапе интерпретации уже полученных результатов. Их основной принцип заключается в автоматическом объединении результатов проведённых ранее исследований.
1. Neurosynth: соотносит психологические параметры с активацией или функциональной связностью на фМРТ.
2. NeuroQuery: на основе свободного текстового запроса (например, "spatial memory in prefrontal cortex ") предсказывает распределение активности фМРТ. Основное отличие от Neurosynth заключается в том, что позволяет проанализировать запрос, выходящий за рамки существующей литературы.
3. ERPscanr: соотносит всевозможные компоненты вызванных потенциалов с когнитивными доменами (например, восприятием или памятью) или с конкретными расстройствами.
{kind=link}
#анонс #resources
Сейчас ожидаю самолёт, который отправляется в Ингушетию. Там пройдёт научная школа по экспериментальной и теоретической нейробиологии от научного центра «Идея».
В прошлом году я участвовала в аналогичной школе, организованной тем же центром, и определённо это был полезный опыт, поскольку в России сложно найти мероприятия, в рамках которых происходит настолько интенсивное погружение одновременно в нейробиологическое, математическое и физическое описание активности нейронов и их сетей.
В течение школы планирую оставлять в канале заметки по некоторым лекциям и семинарам, а пока прилагаю ссылку на записи лекций с прошлогодней школы.
Сейчас ожидаю самолёт, который отправляется в Ингушетию. Там пройдёт научная школа по экспериментальной и теоретической нейробиологии от научного центра «Идея».
В прошлом году я участвовала в аналогичной школе, организованной тем же центром, и определённо это был полезный опыт, поскольку в России сложно найти мероприятия, в рамках которых происходит настолько интенсивное погружение одновременно в нейробиологическое, математическое и физическое описание активности нейронов и их сетей.
В течение школы планирую оставлять в канале заметки по некоторым лекциям и семинарам, а пока прилагаю ссылку на записи лекций с прошлогодней школы.
brain.scientificideas.org
Научный Центр «Идея» / IDEAS Center
IDeAS: Inter-Disciplinary & Advanced Studies Center
IDEAS Neuroscience School. Начало
#анонс #resources
В данный момент идёт открытие научной школы по экспериментальной и теоретической нейробиологии. На официальном сайте стала доступна ссылка с трансляцией, используя которую можно послушать лекции и семинары.
#анонс #resources
В данный момент идёт открытие научной школы по экспериментальной и теоретической нейробиологии. На официальном сайте стала доступна ссылка с трансляцией, используя которую можно послушать лекции и семинары.
Открытые датасеты по нейровизуализации
#resources
Обнаружила полезную платформу, на которой можно найти большое количество данных ЭЭГ, МЭГ, ПЭТ и МРТ. Число датасетов достигает нескольких сотен, доступна фильтрация по характеристикам участников, исследуемому заболеванию или когнитивной задаче.
#resources
Обнаружила полезную платформу, на которой можно найти большое количество данных ЭЭГ, МЭГ, ПЭТ и МРТ. Число датасетов достигает нескольких сотен, доступна фильтрация по характеристикам участников, исследуемому заболеванию или когнитивной задаче.
Elicit — ваш научный ассистент
#resources
Если вы хотите найти ответ на ваш исследовательский вопрос, можно воспользоваться сервисом Elicit, который на основе использования языковых моделей автоматизирует поиск и обработку информации в научных статьях.
Что он умеет делать (см. скрины):
- Находить статьи по исследовательскому вопросу и делать краткую выжимку из каждой аннотации, а также из наиболее цитируемых публикаций.
- Отвечать на вопросы по отдельной статье.
- Устраивать мозговой штурм, формулируя исследовательские вопросы в соответствии с заданной тематикой.
- Определять зависимые и независимые переменные в соответствии с гипотезой.
- Перефразировать предложение другими словами.
- Выстраивать логическую цепочку от одного утверждения к другому.
- Дополнять исходное утверждение новой информацией.
- Смоделировать причины, по которым исследовательский план может провалиться.
и т. д.
Функционал Elicit постоянно пополняется. Более того, можно самостоятельно добавлять собственные функции. Естественно, в результатах периодически появляются огрехи типичные для решений на основе ИИ, но, тем не менее, даже в текущем виде Elicit может оказаться очень полезным на этапе написания научных обзоров, формирования гипотез и планирования проектов.
Кто знает, может быть, когда-нибудь мы доживем до разработки автоматического писателя научных статей 😎
#resources
Если вы хотите найти ответ на ваш исследовательский вопрос, можно воспользоваться сервисом Elicit, который на основе использования языковых моделей автоматизирует поиск и обработку информации в научных статьях.
Что он умеет делать (см. скрины):
- Находить статьи по исследовательскому вопросу и делать краткую выжимку из каждой аннотации, а также из наиболее цитируемых публикаций.
- Отвечать на вопросы по отдельной статье.
- Устраивать мозговой штурм, формулируя исследовательские вопросы в соответствии с заданной тематикой.
- Определять зависимые и независимые переменные в соответствии с гипотезой.
- Перефразировать предложение другими словами.
- Выстраивать логическую цепочку от одного утверждения к другому.
- Дополнять исходное утверждение новой информацией.
- Смоделировать причины, по которым исследовательский план может провалиться.
и т. д.
Функционал Elicit постоянно пополняется. Более того, можно самостоятельно добавлять собственные функции. Естественно, в результатах периодически появляются огрехи типичные для решений на основе ИИ, но, тем не менее, даже в текущем виде Elicit может оказаться очень полезным на этапе написания научных обзоров, формирования гипотез и планирования проектов.
Кто знает, может быть, когда-нибудь мы доживем до разработки автоматического писателя научных статей 😎
Незаменимая прихоть
#resources
О ChatGPT говорят многие и настолько часто, что я даже не планировала посвящать этому отдельный пост. Однако импровизированный опрос моих коллег, однокурсников и студентов показал, что некоторые воспринимают его как очередную забавную ИИ-игрушку и все-таки существует необходимость в освещении функционала ChatGPT, который может пригодиться именно в научной работе.
В каких задачах ChatGPT может помочь ученому?
1. Формирование исследовательского вопроса, гипотезы, дизайна исследования, а в целом — любой brainstorming.
2. Изложение подробных инструкций того, как решить задачу с возможностью последующих уточнений в режиме диалога, который ИИ “запоминает” целиком. Например, когда я обсудила с чатом некоторые детали своей диссертации, он предложил специфичные именно для моей темы решения, которые в самостоятельном режиме я в ряде ситуаций могла бы выкристаллизовывать путем проб и ошибок на протяжении недель или месяцев.
3. Создание готового кода для решения задач, которые можно описывать на разном уровне абстракции. Например, “Напиши код, чтобы решить задачу оптимизации для таких-то данных и нарисуй график для таких-то результатов”.
4. Правка багов в исходном коде и объяснение, в чем заключаются ошибки.
5. Написание академического текста (или даже поэтического, но это уже вне научной деятельности) на заданную тему (может пригодиться для теоретического введения статьи или абстракта).
6. Правки, “облагораживание” или парафраз исходного текста, выделение из него основных тезисов. Это может помочь даже в подготовке лекции, если вы, как и я, испытываете сложности с “формулировками, понятными 10-летнему ребенку”.
Подводные камни
ChatGPT нередко испытывает “галлюцинации” и может искажать фактическую информацию, облекая эти искажения в непротиворечивый текст. Однажды он даже был пойман на том, что сгенерировал список несуществующих статей по заданной теме. Поэтому не следует опираться на него как на поисковую систему. Если вам нужен ИИ-ассистент для автоматического поиска по содержательной части научных исследований, рекомендую использовать Elicit, о котором я писала ранее. Если Вы ощущаете, что ChatGPT предоставляет не совсем точную информацию, последующие наводящие вопросы могут убрать противоречия.
Со стороны использование ChatGPT может показаться прихотью. Но если грамотно включить его в свою работу и не впадать в крайности, он повышает эффективность в разы настолько, что отказаться от него почти невозможно (в нашей лаборатории уже есть несколько жертв, среди которых — и я).
#resources
О ChatGPT говорят многие и настолько часто, что я даже не планировала посвящать этому отдельный пост. Однако импровизированный опрос моих коллег, однокурсников и студентов показал, что некоторые воспринимают его как очередную забавную ИИ-игрушку и все-таки существует необходимость в освещении функционала ChatGPT, который может пригодиться именно в научной работе.
В каких задачах ChatGPT может помочь ученому?
1. Формирование исследовательского вопроса, гипотезы, дизайна исследования, а в целом — любой brainstorming.
2. Изложение подробных инструкций того, как решить задачу с возможностью последующих уточнений в режиме диалога, который ИИ “запоминает” целиком. Например, когда я обсудила с чатом некоторые детали своей диссертации, он предложил специфичные именно для моей темы решения, которые в самостоятельном режиме я в ряде ситуаций могла бы выкристаллизовывать путем проб и ошибок на протяжении недель или месяцев.
3. Создание готового кода для решения задач, которые можно описывать на разном уровне абстракции. Например, “Напиши код, чтобы решить задачу оптимизации для таких-то данных и нарисуй график для таких-то результатов”.
4. Правка багов в исходном коде и объяснение, в чем заключаются ошибки.
5. Написание академического текста (или даже поэтического, но это уже вне научной деятельности) на заданную тему (может пригодиться для теоретического введения статьи или абстракта).
6. Правки, “облагораживание” или парафраз исходного текста, выделение из него основных тезисов. Это может помочь даже в подготовке лекции, если вы, как и я, испытываете сложности с “формулировками, понятными 10-летнему ребенку”.
Подводные камни
ChatGPT нередко испытывает “галлюцинации” и может искажать фактическую информацию, облекая эти искажения в непротиворечивый текст. Однажды он даже был пойман на том, что сгенерировал список несуществующих статей по заданной теме. Поэтому не следует опираться на него как на поисковую систему. Если вам нужен ИИ-ассистент для автоматического поиска по содержательной части научных исследований, рекомендую использовать Elicit, о котором я писала ранее. Если Вы ощущаете, что ChatGPT предоставляет не совсем точную информацию, последующие наводящие вопросы могут убрать противоречия.
Со стороны использование ChatGPT может показаться прихотью. Но если грамотно включить его в свою работу и не впадать в крайности, он повышает эффективность в разы настолько, что отказаться от него почти невозможно (в нашей лаборатории уже есть несколько жертв, среди которых — и я).
В поисках золотого стандарта обработки данных МЭГ и ЭЭГ (пост об узконаправленной профессиональной боли)
#neuroimaging #resources
Все время работы в сфере нейровизуализации я сталкиваюсь с тем, что почти у каждого исследователя – своя кухня обработки данных активности мозга. Более того, с накоплением опыта я сама изменяю свои внутренние критерии принятия того или иного решения в обработке, делая их менее и менее субъективными.
На семинарах по анализу МЭГ/ЭЭГ я специально показываю своим студентам ситуации, в которых тот или иной подход или метод анализа не срабатывает или выдает искаженные результаты. Эти примеры демонстрируют, что, к сожалению, пока не разработан золотой стандарт по выбору универсальных параметров обработки, соблюдающих баланс между частотными и временными характеристиками, между шумом и значимым сигналом, между точностью локализации активности мозга и ее пространственной ограниченностью и т. д. Отсутствие этого золотого стандарта вносит свой вклад в кризис репликации результатов исследований.
Тем не менее, существуют публикации, которые содержат ряд рекомендаций или наблюдений по обработке данных и проведению исследований, которые могут оказаться полезными:
1. FLUX: пайплайн по анализу МЭГ
В пайплайне задаются параметры снижения шума с учетом конфигурации сенсоров, избавления от артефактов, построения пространства кортикальных источников достаточного разрешения для реконструкции их активности. В пайплайне делается акцент на анализе мощности именно осцилляторной активности, поэтому в качестве способа решения обратной задачи используется пространственная фильтрация на основе кросс-спектральной матрицы с использованием DICS-бимформера. Скрипты пайплайна для MNE Python и FieldTrip находятся в открытом доступе. С одной стороны, пайплайн не изобилует деталями и некоторые результаты реконструкции активности источников на первый взгляд не кажутся "чистыми", но, с другой стороны, за каждым шагом и параметром стоит эксплицитно обозначенная логика. Пайплайн вполне можно использовать для самообразования или в качестве отправной точки для анализа данных, в которых важны осцилляторные характеристики сигнала. Также отдельно ценно, что в конце каждого скрипта авторы прилагают текст с примером того, как излагать параметры каждого этапа в публикациях или при пре-регистрации исследования для возможности последующей репликации.
2. PREP: пайплайн по анализу ЭЭГ
Этот пайплайн касается предобработки ЭЭГ с большим акцентом на работе с плохими каналами (для ЭЭГ это более актуально, чем для МЭГ) и с выбором устойчивого референта. Доступны скрипты на MATLAB и плагин для тулбокса EEGLAB (выбор, как мне кажется, не самый оптимальный, потому что у EEGLAB меньше степеней свободы, чем у Brainstorm или FieldTrip).
3. Сопоставление бимформеров в разных тулбоксах
В этой публикации с использованием симуляций и реальных данных сопоставляются результаты пространственной фильтрации с помощью бимформеров в основных тулбоксах: MNE Python, Brainstorm, FieldTrip и DAiSS. Для любителей MNE Python результаты неутешительные, потому что для высоких значений соотношения сигнал-шум ошибка локализации источников при использовании этого тулбокса оказалась высока. Самым устойчивым оказался Brainstorm, хотя в ряде ситуаций пространственное разрешение результатов было не самым лучшим. Код с пайплайнами доступен по этой ссылке.
#neuroimaging #resources
Все время работы в сфере нейровизуализации я сталкиваюсь с тем, что почти у каждого исследователя – своя кухня обработки данных активности мозга. Более того, с накоплением опыта я сама изменяю свои внутренние критерии принятия того или иного решения в обработке, делая их менее и менее субъективными.
На семинарах по анализу МЭГ/ЭЭГ я специально показываю своим студентам ситуации, в которых тот или иной подход или метод анализа не срабатывает или выдает искаженные результаты. Эти примеры демонстрируют, что, к сожалению, пока не разработан золотой стандарт по выбору универсальных параметров обработки, соблюдающих баланс между частотными и временными характеристиками, между шумом и значимым сигналом, между точностью локализации активности мозга и ее пространственной ограниченностью и т. д. Отсутствие этого золотого стандарта вносит свой вклад в кризис репликации результатов исследований.
Тем не менее, существуют публикации, которые содержат ряд рекомендаций или наблюдений по обработке данных и проведению исследований, которые могут оказаться полезными:
1. FLUX: пайплайн по анализу МЭГ
В пайплайне задаются параметры снижения шума с учетом конфигурации сенсоров, избавления от артефактов, построения пространства кортикальных источников достаточного разрешения для реконструкции их активности. В пайплайне делается акцент на анализе мощности именно осцилляторной активности, поэтому в качестве способа решения обратной задачи используется пространственная фильтрация на основе кросс-спектральной матрицы с использованием DICS-бимформера. Скрипты пайплайна для MNE Python и FieldTrip находятся в открытом доступе. С одной стороны, пайплайн не изобилует деталями и некоторые результаты реконструкции активности источников на первый взгляд не кажутся "чистыми", но, с другой стороны, за каждым шагом и параметром стоит эксплицитно обозначенная логика. Пайплайн вполне можно использовать для самообразования или в качестве отправной точки для анализа данных, в которых важны осцилляторные характеристики сигнала. Также отдельно ценно, что в конце каждого скрипта авторы прилагают текст с примером того, как излагать параметры каждого этапа в публикациях или при пре-регистрации исследования для возможности последующей репликации.
2. PREP: пайплайн по анализу ЭЭГ
Этот пайплайн касается предобработки ЭЭГ с большим акцентом на работе с плохими каналами (для ЭЭГ это более актуально, чем для МЭГ) и с выбором устойчивого референта. Доступны скрипты на MATLAB и плагин для тулбокса EEGLAB (выбор, как мне кажется, не самый оптимальный, потому что у EEGLAB меньше степеней свободы, чем у Brainstorm или FieldTrip).
3. Сопоставление бимформеров в разных тулбоксах
В этой публикации с использованием симуляций и реальных данных сопоставляются результаты пространственной фильтрации с помощью бимформеров в основных тулбоксах: MNE Python, Brainstorm, FieldTrip и DAiSS. Для любителей MNE Python результаты неутешительные, потому что для высоких значений соотношения сигнал-шум ошибка локализации источников при использовании этого тулбокса оказалась высока. Самым устойчивым оказался Brainstorm, хотя в ряде ситуаций пространственное разрешение результатов было не самым лучшим. Код с пайплайнами доступен по этой ссылке.
Артефакты и размер эффекта
#resources #statistics
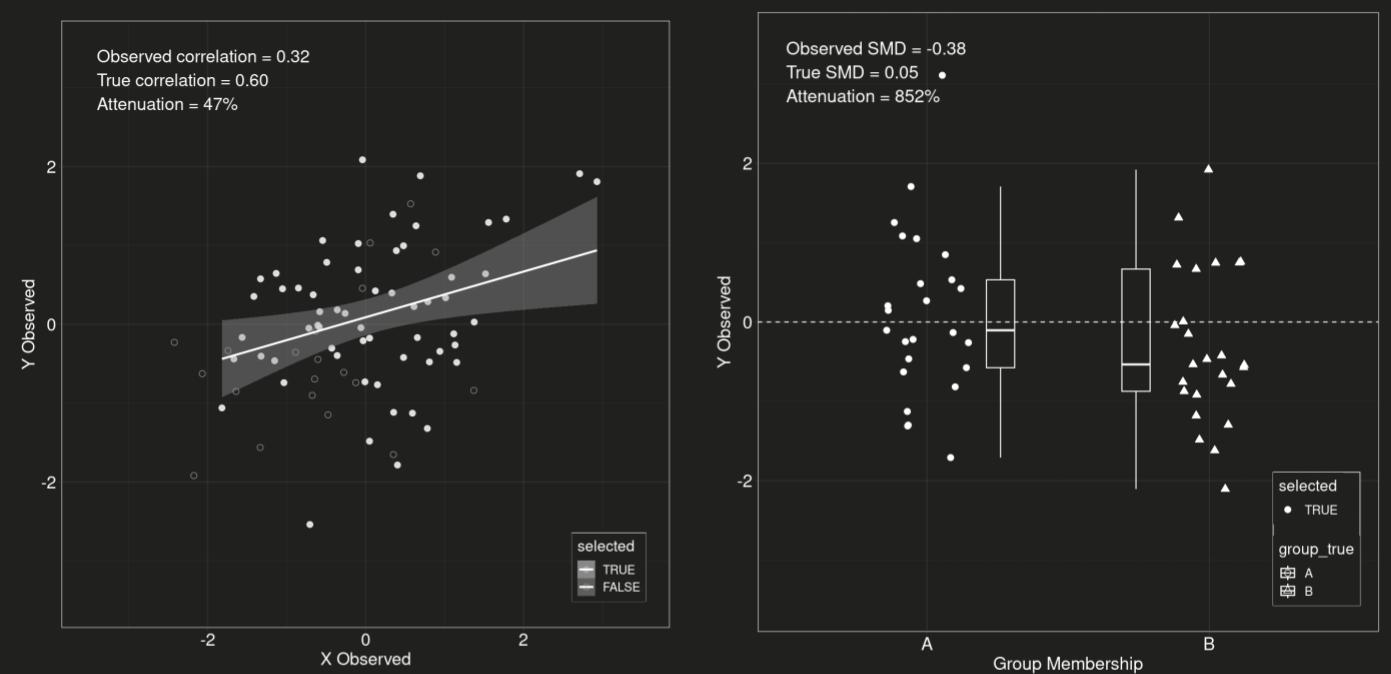
Нашла отличный интерактивный тулбокс от Matthew B. Jané по визуализации статистических артефактов, которые искажают размер эффекта. Сопровождающие теоретические материалы с формулами и кодом можно найти здесь. В этих материалах рассматриваются такие артефакты, как небольшая величина выборки, ошибки измерения, понижающие показатели связи между факторами, а также ограничения доступного диапазона величин. Для каждого случая предлагаются способы коррекции возникших искажений.
Один из простейших примеров работы тулбокса (см. скрин): демонстрация того, как недостаточный объем выборки приводит к заниженным показателям корреляции и завышенным показателям стандартизованной разницы средних.
#resources #statistics
Нашла отличный интерактивный тулбокс от Matthew B. Jané по визуализации статистических артефактов, которые искажают размер эффекта. Сопровождающие теоретические материалы с формулами и кодом можно найти здесь. В этих материалах рассматриваются такие артефакты, как небольшая величина выборки, ошибки измерения, понижающие показатели связи между факторами, а также ограничения доступного диапазона величин. Для каждого случая предлагаются способы коррекции возникших искажений.
Один из простейших примеров работы тулбокса (см. скрин): демонстрация того, как недостаточный объем выборки приводит к заниженным показателям корреляции и завышенным показателям стандартизованной разницы средних.
{kind=link}
Голодные судьи против статистики
#psychology #resources #statistics
На очень полезном ресурсе по статистике Д. Лакенса приведен пример того, как можно пойти на поводу у слишком красивых результатов.
Нередко в качестве иллюстрации того, как сильно наши решения зависят от косвенных факторов, упоминается исследование, в котором обнаружилось, что судьи выносят более жесткие приговоры до обеда, чем после обеда. Напрашивается простая интерпретация: справедливости не существует, когда ты голоден (не обессудьте – клише). Однако не все так просто.
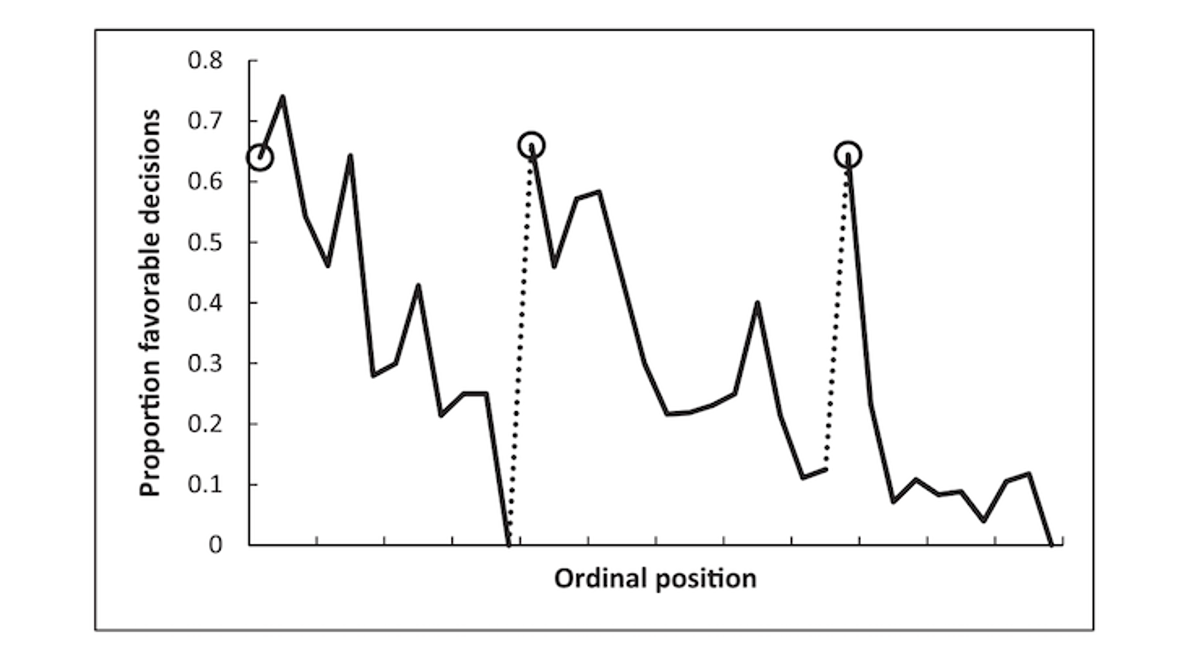
Во-первых, обратимся к графику из статьи. Он показывает пропорцию решений в пользу подсудимых в течение всего дня (общее количество анализируемых дней составило 50). Мы видим, что в самом начале дня судьи отпускали на волю 65 % подсудимых, а затем этот показатель резко падал до нуля. После перерыва показатель cнова возвращался к 65 % и так же быстро падал. После второго перерыва ситуация повторялась. Такая повторяемость и такие резкие спады выглядят очень подозрительно.
Во-вторых, выяснилось, что размер эффекта у наблюдаемых тенденций чрезмерно высокий. Напомню, что хоть мы все подспудно и гонимся на значимыми p-values, они констатируют лишь наличие эффекта, а его размер нужно количественно оценивать дополнительно. Например, если разница в среднем росте между детьми и подростками составит 60 см, то это станет размером эффекта. Поделив эту разность на стандартное отклонение, мы получим стандартизованную оценку (Cohen's d, d Коэна). Если d=1, то это значит, что две группы отличаются на одно стандартное отклонение. d=0.2 считают малым размером эффекта, d=0.5 – средним, d>0.8 – большим.
В исследовании про судей размер эффекта составил d=1.96! В психологических экспериментах такие размеры эффекта едва ли достижимы. В частности, Лакенс приводит пример исследования, в котором d=2 соответствует различию в росте 21-летнего взрослого мужчины и женщины в Нидерландах. Оно составляет 13 сантиметров, что весьма ощутимо. Если же переключаться на размеры эффекта в психологии, то близкие значения d Коэна могли достигаться лишь в тех случаях, когда независимая и зависимая переменные составляли чуть ли не тавтологию (например, взаимодействие харизмы и лидерства, социальной девиации и исключения из общества и т. д.)
Таким образом, обнаруженный эффект явно не может объясняться такими опосредованными механизмами, как голод и усталость. Было бы это так, мы бы наблюдали этот огромный эффект напрямую в виде хаоса и ментальных провалов в предобеденное время. Впрочем, если обращаться к нашему внутрилабораторному опыту, иногда это похоже на правду, но точно не дотягивает до d=1.96.
Наиболее вероятным объяснением полученных результатов может являться то, что рассмотрение дел в суде в каждой из сессий производилось не в случайном порядке: например, "простые" дела, в результате которых подсудимый с большой вероятностью заслуживал освобождение, могли рассматриваться первыми.
Это наглядный пример того, что красивая статистика без правдоподобной интерпретации, соответствующей ей, приводит к заблуждениям. И такие примеры могут послужить поводом к включению в эксперименты 'maximum positive controls' – экспериментальных условий, которые задают верхнюю границу возможного размера эффекта в заданной парадигме.
#psychology #resources #statistics
На очень полезном ресурсе по статистике Д. Лакенса приведен пример того, как можно пойти на поводу у слишком красивых результатов.
Нередко в качестве иллюстрации того, как сильно наши решения зависят от косвенных факторов, упоминается исследование, в котором обнаружилось, что судьи выносят более жесткие приговоры до обеда, чем после обеда. Напрашивается простая интерпретация: справедливости не существует, когда ты голоден (не обессудьте – клише). Однако не все так просто.
Во-первых, обратимся к графику из статьи. Он показывает пропорцию решений в пользу подсудимых в течение всего дня (общее количество анализируемых дней составило 50). Мы видим, что в самом начале дня судьи отпускали на волю 65 % подсудимых, а затем этот показатель резко падал до нуля. После перерыва показатель cнова возвращался к 65 % и так же быстро падал. После второго перерыва ситуация повторялась. Такая повторяемость и такие резкие спады выглядят очень подозрительно.
Во-вторых, выяснилось, что размер эффекта у наблюдаемых тенденций чрезмерно высокий. Напомню, что хоть мы все подспудно и гонимся на значимыми p-values, они констатируют лишь наличие эффекта, а его размер нужно количественно оценивать дополнительно. Например, если разница в среднем росте между детьми и подростками составит 60 см, то это станет размером эффекта. Поделив эту разность на стандартное отклонение, мы получим стандартизованную оценку (Cohen's d, d Коэна). Если d=1, то это значит, что две группы отличаются на одно стандартное отклонение. d=0.2 считают малым размером эффекта, d=0.5 – средним, d>0.8 – большим.
В исследовании про судей размер эффекта составил d=1.96! В психологических экспериментах такие размеры эффекта едва ли достижимы. В частности, Лакенс приводит пример исследования, в котором d=2 соответствует различию в росте 21-летнего взрослого мужчины и женщины в Нидерландах. Оно составляет 13 сантиметров, что весьма ощутимо. Если же переключаться на размеры эффекта в психологии, то близкие значения d Коэна могли достигаться лишь в тех случаях, когда независимая и зависимая переменные составляли чуть ли не тавтологию (например, взаимодействие харизмы и лидерства, социальной девиации и исключения из общества и т. д.)
Таким образом, обнаруженный эффект явно не может объясняться такими опосредованными механизмами, как голод и усталость. Было бы это так, мы бы наблюдали этот огромный эффект напрямую в виде хаоса и ментальных провалов в предобеденное время. Впрочем, если обращаться к нашему внутрилабораторному опыту, иногда это похоже на правду, но точно не дотягивает до d=1.96.
Наиболее вероятным объяснением полученных результатов может являться то, что рассмотрение дел в суде в каждой из сессий производилось не в случайном порядке: например, "простые" дела, в результате которых подсудимый с большой вероятностью заслуживал освобождение, могли рассматриваться первыми.
Это наглядный пример того, что красивая статистика без правдоподобной интерпретации, соответствующей ей, приводит к заблуждениям. И такие примеры могут послужить поводом к включению в эксперименты 'maximum positive controls' – экспериментальных условий, которые задают верхнюю границу возможного размера эффекта в заданной парадигме.
{kind=link}
Атласы для нейроисследователей и врачей
#resources #tools
Некоторое время назад я публиковала пост со ссылками на ресурсы с автоматическим объединением результатов нейроисследований по соотнесению психологических параметров и данных фМРТ, а также вызванных потенциалов, выделенных на основе ЭЭГ.
Дополнением к этим коллекциям могут стать онлайн-атласы, которые можно использовать для тренировки "насмотренности":
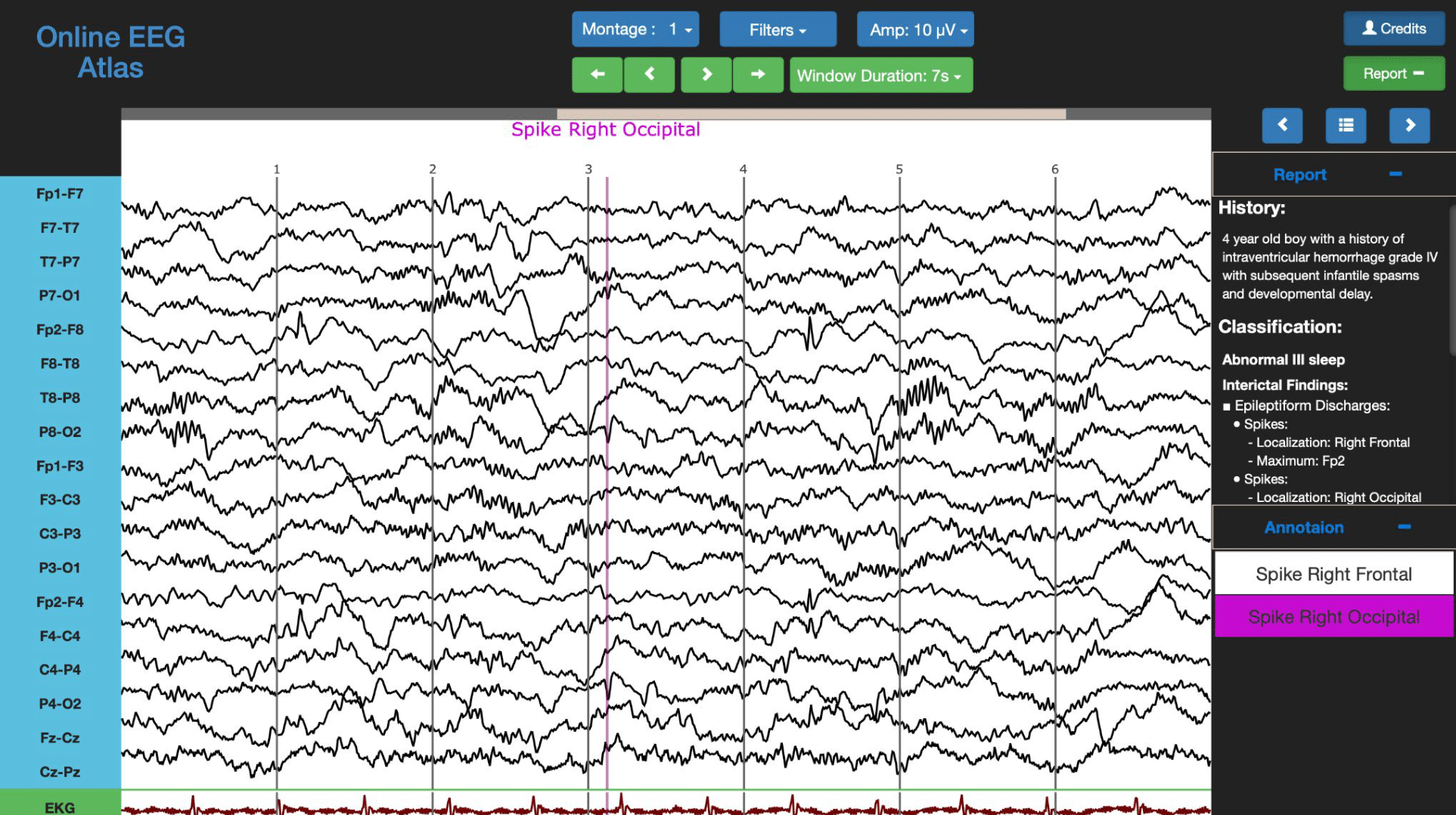
1. EEG Atlas. В этом атласе можно выбрать возрастную группу, состояние сознания (бодрствование, сон, кома), степень ЭЭГ-нарушений, указать наличие конкретных паттернов (межсудорожные спайки, моторные ритмы и т. д. ) и получить пример ЭЭГ-сегмента с выделенными паттернами, соответствующими запросу. В интерактивном режиме можно менять монтаж ЭЭГ. В ряде примеров дополнительно доступны аннотация из истории болезни пациента или описание свойств самих наблюдаемых паттернов.
2. EEGpedia: ЭЭГ-википедия с описаниями и примерами клинических, стандартных физиологических паттернов и артефактов. Дополнительно есть раздел с квизом, в котором по одному примеру ЭЭГ нужно определить диагноз (правда, судя по всему, этот раздел не особо обновляется).
3. Central XNAT: база, в которой по ключевым словам и параметрам можно найти примеры МРТ, ПЭТ или КТ и изучить их во встроенном просмотрщике.
4. Radiology Masterclass: галерея КТ мозга с интерактивными аннотациями для различных диагнозов. Там же есть квиз для самопроверки.
5. NeuroVault: открытый репозиторий фМРТ- и ПЭТ-карт.
6. ACMEGS: образовательные примеры по МЭГ нескольких пациентов.
#resources #tools
Некоторое время назад я публиковала пост со ссылками на ресурсы с автоматическим объединением результатов нейроисследований по соотнесению психологических параметров и данных фМРТ, а также вызванных потенциалов, выделенных на основе ЭЭГ.
Дополнением к этим коллекциям могут стать онлайн-атласы, которые можно использовать для тренировки "насмотренности":
1. EEG Atlas. В этом атласе можно выбрать возрастную группу, состояние сознания (бодрствование, сон, кома), степень ЭЭГ-нарушений, указать наличие конкретных паттернов (межсудорожные спайки, моторные ритмы и т. д. ) и получить пример ЭЭГ-сегмента с выделенными паттернами, соответствующими запросу. В интерактивном режиме можно менять монтаж ЭЭГ. В ряде примеров дополнительно доступны аннотация из истории болезни пациента или описание свойств самих наблюдаемых паттернов.
2. EEGpedia: ЭЭГ-википедия с описаниями и примерами клинических, стандартных физиологических паттернов и артефактов. Дополнительно есть раздел с квизом, в котором по одному примеру ЭЭГ нужно определить диагноз (правда, судя по всему, этот раздел не особо обновляется).
3. Central XNAT: база, в которой по ключевым словам и параметрам можно найти примеры МРТ, ПЭТ или КТ и изучить их во встроенном просмотрщике.
4. Radiology Masterclass: галерея КТ мозга с интерактивными аннотациями для различных диагнозов. Там же есть квиз для самопроверки.
5. NeuroVault: открытый репозиторий фМРТ- и ПЭТ-карт.
6. ACMEGS: образовательные примеры по МЭГ нескольких пациентов.
{kind=link}
Human Neocortical Neurosolver — от нейрона к сенсорам (почти)
#neuroimaging #programming #resources
Давно не пополняла коллекцию полезных тулбоксов. Несколько дней назад вышла новая версия библиотеки HNN (Human Neocortical Neurosolver) на Python (с описанием исходного программного обеспечения можно ознакомиться в этой публикации).
Ценность этой библиотеки в том, что в очень user-friendly формате она позволяет соотносить МЭГ/ЭЭГ данные с клеточной активностью нейронов, их порождающей. Работать можно, в частности, с вызванными потенциалами или осцилляторной активностью. На фоне оптимистичности подхода можно выделить два ограничения:
1. Фактически основной ингредиент тулбокса — это моделирование активности кортикальных источников в виде первичного тока с использованием биофизической модели нейронов. Соотнесение же с измерениями на МЭГ/ЭЭГ сенсорах осуществляется за счет сопоставления смоделированной активности кортикальных источников и той, которая была реконструирована на основе МЭГ/ЭЭГ с помощью методов решения обратной задачи. Решение обратной задачи в этом случае — отдельный изолированный шаг. О сложностях, которые его могут сопровождать, я писала в одном из предыдущих постов. Получается, что биофизическая модель описывает переход с микроуровня клеток на макроуровень кортикальных источников, но не на уровень сенсоров. Т. е. на выходе мы получаем сопоставление моделей “нейрон-диполь” и “сенсор-диполь”. Это очевидным образом может порождать искажения.
2. Сама используемая биофизическая модель опирается на архитектуру колонок пирамидальных нейронов неокортекса и не затрагивает иные возможные архитектуры. Впрочем, сами используемые параметры (пропорции возбуждения/торможения, специфичные для каждого слоя синаптические взаимодействия и характеристики спайковой активности) обеспечивают некоторые степени свободы.
Несмотря на текущие ограничения подхода, он открывает пространство для тестирования гипотез. В частности, с помощью HNN получилось сформировать предсказания об источниках спонтанных бета-осцилляций в неокортексе, которые затем были подтверждены на основе инвазивных данных мышей и обезьян.
На видео — пример симуляции вызванной активности. А по этой ссылке можно найти пример скрипта, который решает обратную задачу для соматосенсорной вызванной активности, наблюдаемой в МЭГ-данных, а затем моделирует сеть нейронов, репродуцирующую активность соответствующих источников.
#neuroimaging #programming #resources
Давно не пополняла коллекцию полезных тулбоксов. Несколько дней назад вышла новая версия библиотеки HNN (Human Neocortical Neurosolver) на Python (с описанием исходного программного обеспечения можно ознакомиться в этой публикации).
Ценность этой библиотеки в том, что в очень user-friendly формате она позволяет соотносить МЭГ/ЭЭГ данные с клеточной активностью нейронов, их порождающей. Работать можно, в частности, с вызванными потенциалами или осцилляторной активностью. На фоне оптимистичности подхода можно выделить два ограничения:
1. Фактически основной ингредиент тулбокса — это моделирование активности кортикальных источников в виде первичного тока с использованием биофизической модели нейронов. Соотнесение же с измерениями на МЭГ/ЭЭГ сенсорах осуществляется за счет сопоставления смоделированной активности кортикальных источников и той, которая была реконструирована на основе МЭГ/ЭЭГ с помощью методов решения обратной задачи. Решение обратной задачи в этом случае — отдельный изолированный шаг. О сложностях, которые его могут сопровождать, я писала в одном из предыдущих постов. Получается, что биофизическая модель описывает переход с микроуровня клеток на макроуровень кортикальных источников, но не на уровень сенсоров. Т. е. на выходе мы получаем сопоставление моделей “нейрон-диполь” и “сенсор-диполь”. Это очевидным образом может порождать искажения.
2. Сама используемая биофизическая модель опирается на архитектуру колонок пирамидальных нейронов неокортекса и не затрагивает иные возможные архитектуры. Впрочем, сами используемые параметры (пропорции возбуждения/торможения, специфичные для каждого слоя синаптические взаимодействия и характеристики спайковой активности) обеспечивают некоторые степени свободы.
Несмотря на текущие ограничения подхода, он открывает пространство для тестирования гипотез. В частности, с помощью HNN получилось сформировать предсказания об источниках спонтанных бета-осцилляций в неокортексе, которые затем были подтверждены на основе инвазивных данных мышей и обезьян.
На видео — пример симуляции вызванной активности. А по этой ссылке можно найти пример скрипта, который решает обратную задачу для соматосенсорной вызванной активности, наблюдаемой в МЭГ-данных, а затем моделирует сеть нейронов, репродуцирующую активность соответствующих источников.
YouTube
HNN Event Related Potential
Visualization of cortical activity underlying event related potentials as simulated by the Human Neocortical Neurosolver (HNN). Colors in the network correspond to membrane potential.